


Pandas 的 apply 功能可謂其中一個最重要的數據處理工具。讓我們用例子一齊看看 apply 的強大之處吧!
甚麼是 pandas apply?
簡單來說,pandas 的 apply 是一個在 pandas dataframe 加入新列(Column)的指令。這個指令在整合(Transform)數據時基本上時無可避免,例如我們需要加入新的列,是相加 2 個列的結果等。
除了整合數據以外,我其中一個比較喜歡的用法是搭配 pandas groupby 一起使用,能夠簡單明瞭地把數據分類。
您可能感興趣:Pandas 的 groupby 就是簡單!如何統合數據與文字?
如何使用 pandas apply?
使用 pandas apply 時,我們需要準備一個為這個 apply 度身定做的自訂 Python 功能。
這個 Python 功能讀取一行(Row)pandas dataframe 的數據,並輸出該行在新列(Column)的值。例如,這個功能可以讀取 Column1 和 Column2,並輸出總和。
一個偽代碼(pseudo-code)的例子是:
# 定義 Python 功能 def apply_fx(r): output = r['column1'] + r['column2'] return output # 以 apply_fx 建立新的列(Column) df['column3'] = df.apply(apply_fx, axis=1)
以下我們用一個簡單例子開始解說 pandas apply。
簡單例子:透過 pandas apply 計算 BMI
匯入 pandas 並定義 df。
我們用一個簡單的體重/身高 dataframe 示範如何計算 BMI。
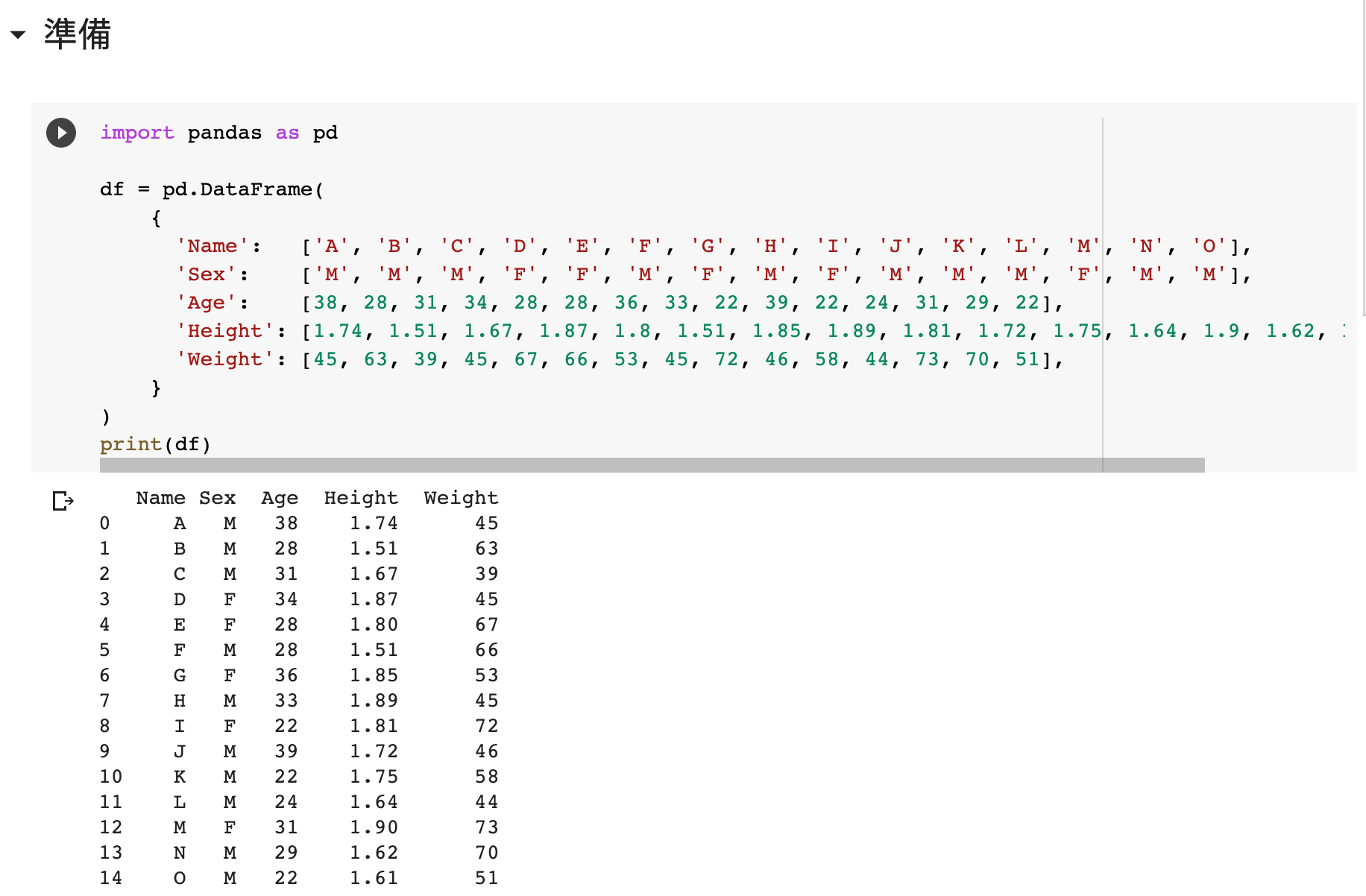
import pandas as pd
df = pd.DataFrame(
{
'Name': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O'],
'Sex': ['M', 'M', 'M', 'F', 'F', 'M', 'F', 'M', 'F', 'M', 'M', 'M', 'F', 'M', 'M'],
'Age': [38, 28, 31, 34, 28, 28, 36, 33, 22, 39, 22, 24, 31, 29, 22],
'Height': [1.74, 1.51, 1.67, 1.87, 1.8, 1.51, 1.85, 1.89, 1.81, 1.72, 1.75, 1.64, 1.9, 1.62, 1.61],
'Weight': [45, 63, 39, 45, 67, 66, 53, 45, 72, 46, 58, 44, 73, 70, 51],
}
)
print(df)
apply 的兩種型態(lambda 與 non-lambda)
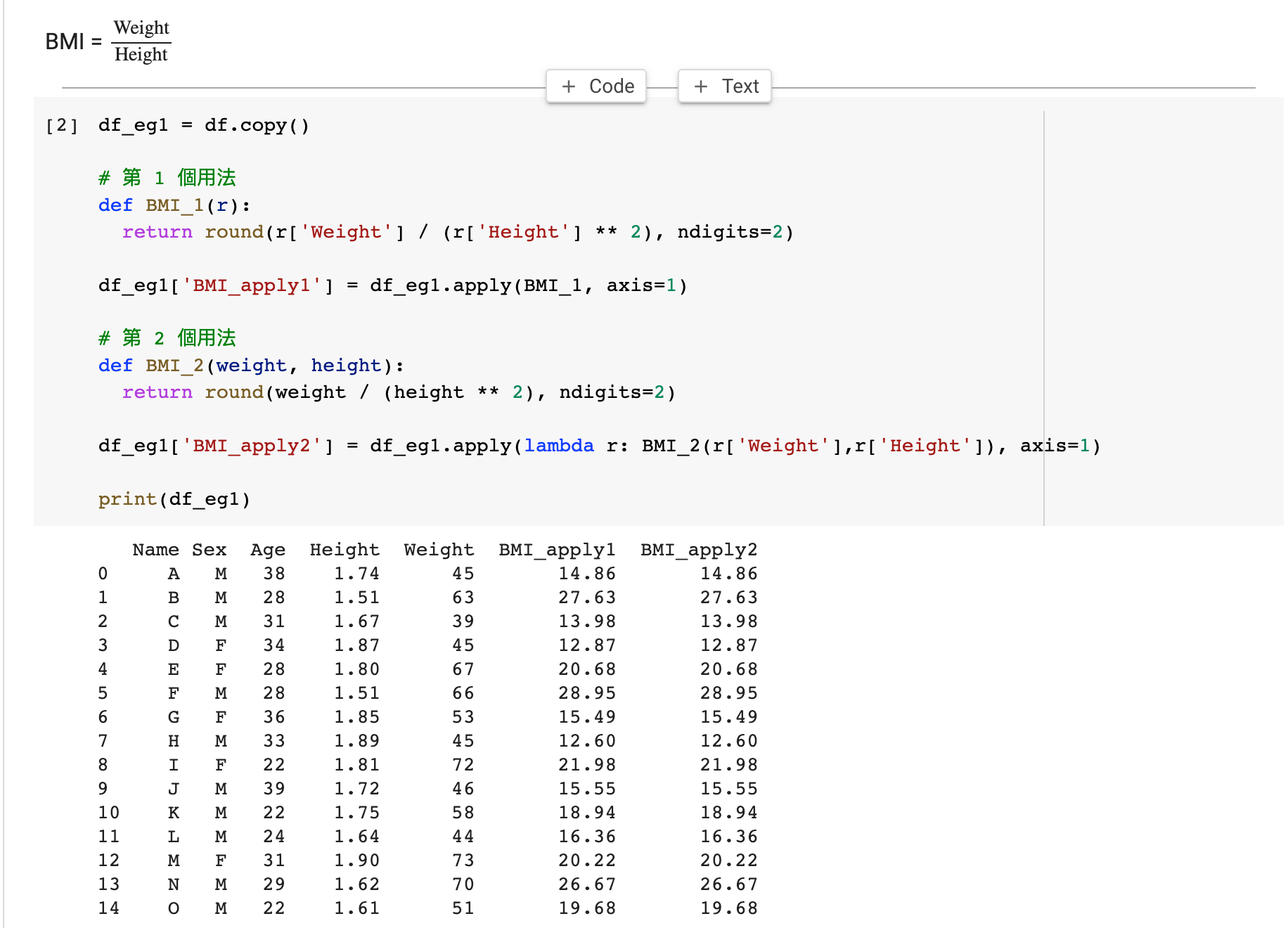
df_eg1 = df.copy() # 第 1 個用法 def BMI_1(r): return round(r['Weight'] / (r['Height'] ** 2), ndigits=2) df_eg1['BMI_apply1'] = df_eg1.apply(BMI_1, axis=1) # 第 2 個用法 def BMI_2(weight, height): return round(weight / (height ** 2), ndigits=2) df_eg1['BMI_apply2'] = df_eg1.apply(lambda r: BMI_2(r['Weight'],r['Height']), axis=1) print(df_eg1)
這裡我們介紹 2 種 apply 的用法,對應 BMI_1 (Python 功能)的是 BMI_apply1,對應 BMI_2 是 BMI_apply2。
我們先定義了 BMI_1 這個功能。留意我們的輸入函數(input)是 r,代表 pandas dataframe 裡面其中一行(row)。
BMI_1 輸出一個 float 數字,是透過融合 r['Weight'] 和 r['Height'] 而成。我們能夠像存取列表(List)一樣,以 r['Column Name'] 獲得每一行(Row)的某一列(Column)的值。
BMI_2 這個功能與 BMI_1 略有不同。分別在於 BMI_2 直接輸入 2 個 float 數字,而不是 pandas dataframe 的行。BMI_2 跟普通的 Python 功能無異。
這兩個用法的結果是一樣,但分別在此:
| 用法 | 解說 |
|---|---|
df.apply(BMI_1, axis=1) | 這裡 apply 的第一個函數(input)是一個 Python 的功能。BMI_1 是一個 Python 的功能(準確來說是一個功能的 Object),所以我們直接把它作為 apply 的主函數。 自訂的 Python 功能(例如 BMI_1)需要處理 pandas dataframe 行(row)的輸入函數。 |
df.apply(lambda r: BMI_2(r['Weight'], r['Height']), axis=1) | 個人比較喜歡這個用法。我們加入 lambda r 的語法,直接在 apply,而不是 BMI_2 指定哪個列(column)是 Weight 和 Height。 這個方法的 Python 功能(BMI_2)只需要處理 weight 和 height 值作為功能輸入函數。好處在於 BMI_2 可以獨立在其他位置使用,而不像 BMI_1 般只能用於 pandas dataframe。 |
apply 裡的函數 axis=1 代表我們以行(Row)作單位,而 0 代表我們以列(Column)作單位。有 99% 的情況我們都以行(Row)為單位!
普通計算(Arithmetics)vs apply
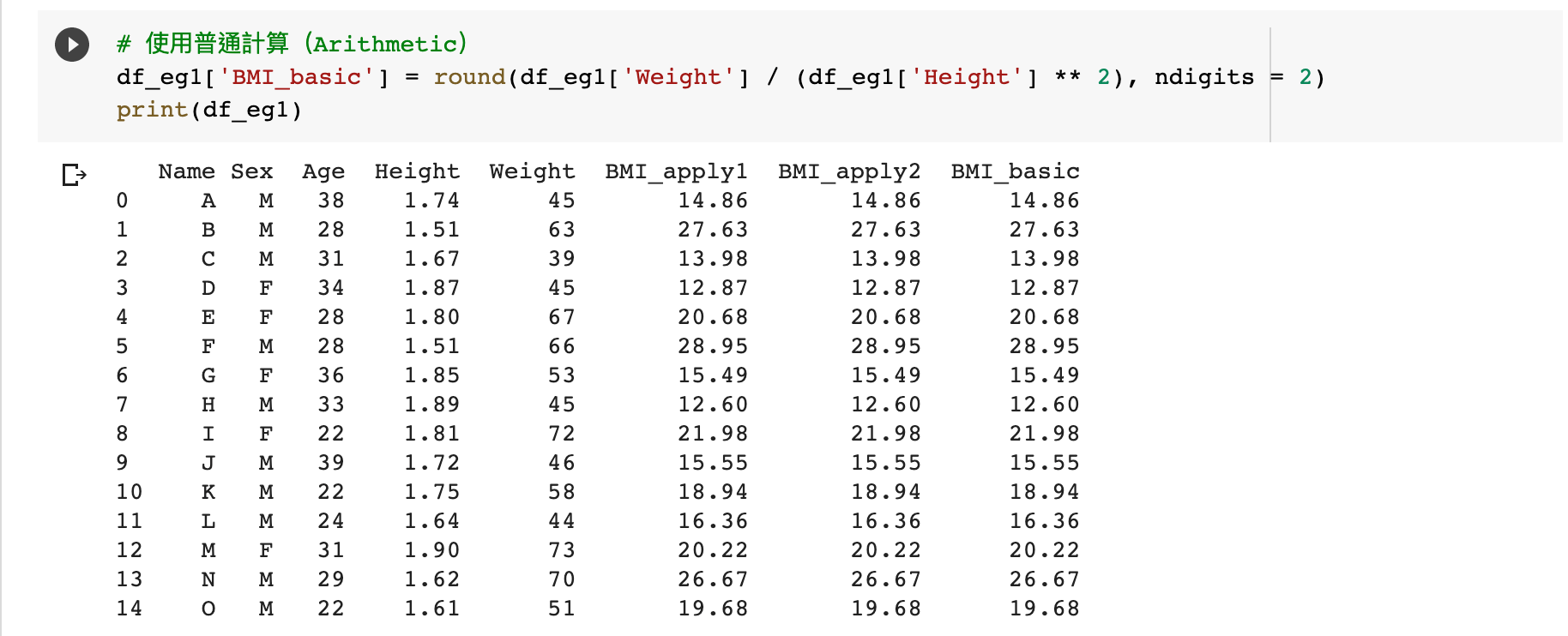
# 使用普通計算(Arithmetic) df_eg1['BMI_basic'] = round(df_eg1['Weight'] / (df_eg1['Height'] ** 2), ndigits = 2) print(df_eg1)
如果我們以普通的計算(Arithmetic)功能,可以直接使用列(Column)作為函數,進行 BMI 的計算。
這也是為什麼我們選擇使用 apply 前,應該先考慮能否以普通的計算功能處理。如果可以的話,我們應該優先使用這種方法,避免把編程變得複雜化。
當然,pandas apply 的流行就意味著 apply 能夠處理更加複雜的編程問題。以下我們繼續介紹 apply 的進階用法。
進階:pandas apply 同時輸出多個列(Column)
除了以上的寫法外,apply 還能夠同時增加多於 1 個列。這個用於有時處理數據會同時輸出 2 個或更多的列(Column),而這些列是互相關聯(dependent),不能獨自計算。
編程偽代碼(pseudo-code):
def my_custom_function(x): # 一些計算 # 回傳結果 return x df = df.apply(my_custom_function, axis=1)
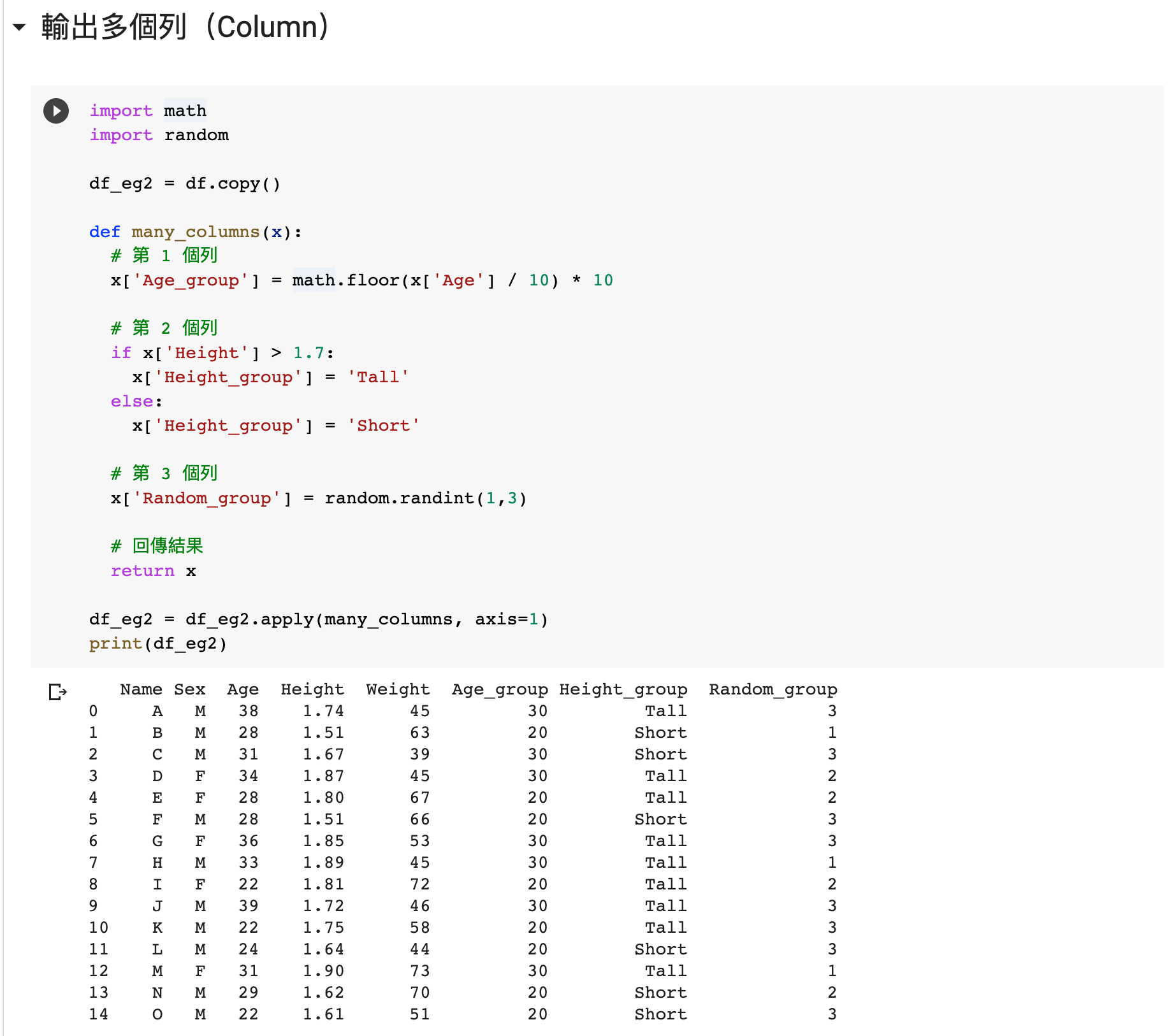
import math
import random
df_eg2 = df.copy()
def many_columns(x):
# 第 1 個列
x['Age_group'] = math.floor(x['Age'] / 10) * 10
# 第 2 個列
if x['Height'] > 1.7:
x['Height_group'] = 'Tall'
else:
x['Height_group'] = 'Short'
# 第 3 個列
x['Random_group'] = random.randint(1,3)
# 回傳結果
return x
df_eg2 = df_eg2.apply(many_columns, axis=1)
print(df_eg2)
在這個例子,我們在原來的 dataframe 增加 3 個列。
留意我們用 1 個自訂功能,many_columns() 去同時輸出 Age_group、Height_group 和 Random_group,然後回傳結果。
與簡單例子不同之處在於上面我們把 apply 的結果輸出成 df['new column'] ,但這裡我們直接把 apply 的結果輸出成 df。前者是 dataframe 的一列(Column),而後者是整個 dataframe。
進階:以 apply 製做自訂數據類型(object)
最後我們介紹一下我認為最精彩的用途,是透過 apply 一炮製做多個自訂的數據類型(object)。
如果你的編程比較複雜和需要用上多個步驟,那麼你可以考慮使用自訂的數據類型協助你。譬如一些會計型的 Python 編程涉及到交易等,那麼有時候自訂一個數據類型專門處理每宗交易會大大縮小編程的複雜性。
定義數據類型(Custom Object)

class Person:
def __init__(self, sex, height, weight, age):
self.sex = sex
self.height = height
self.weight = weight
self.age = age
def describe(self):
if self.sex == 'M':
sex_describe = '男生'
else:
sex_describe = '女生'
if self.height > 1.7:
height_describe = '高高'
else:
height_describe = '矮矮'
if self.weight > 60:
weight_describe = '胖胖'
else:
weight_describe = '瘦瘦'
if self.age > 30:
age_describe = '青年'
else:
age_describe = '少年'
return '我是一個' + height_describe + weight_describe + '的' + age_describe + sex_describe
留意我們先定義了何謂一個「人」(Person)的數據模型,並賦予這個數據模型一個功能去描述這個「人」的特徵。
以 apply 在每行製成數據模型
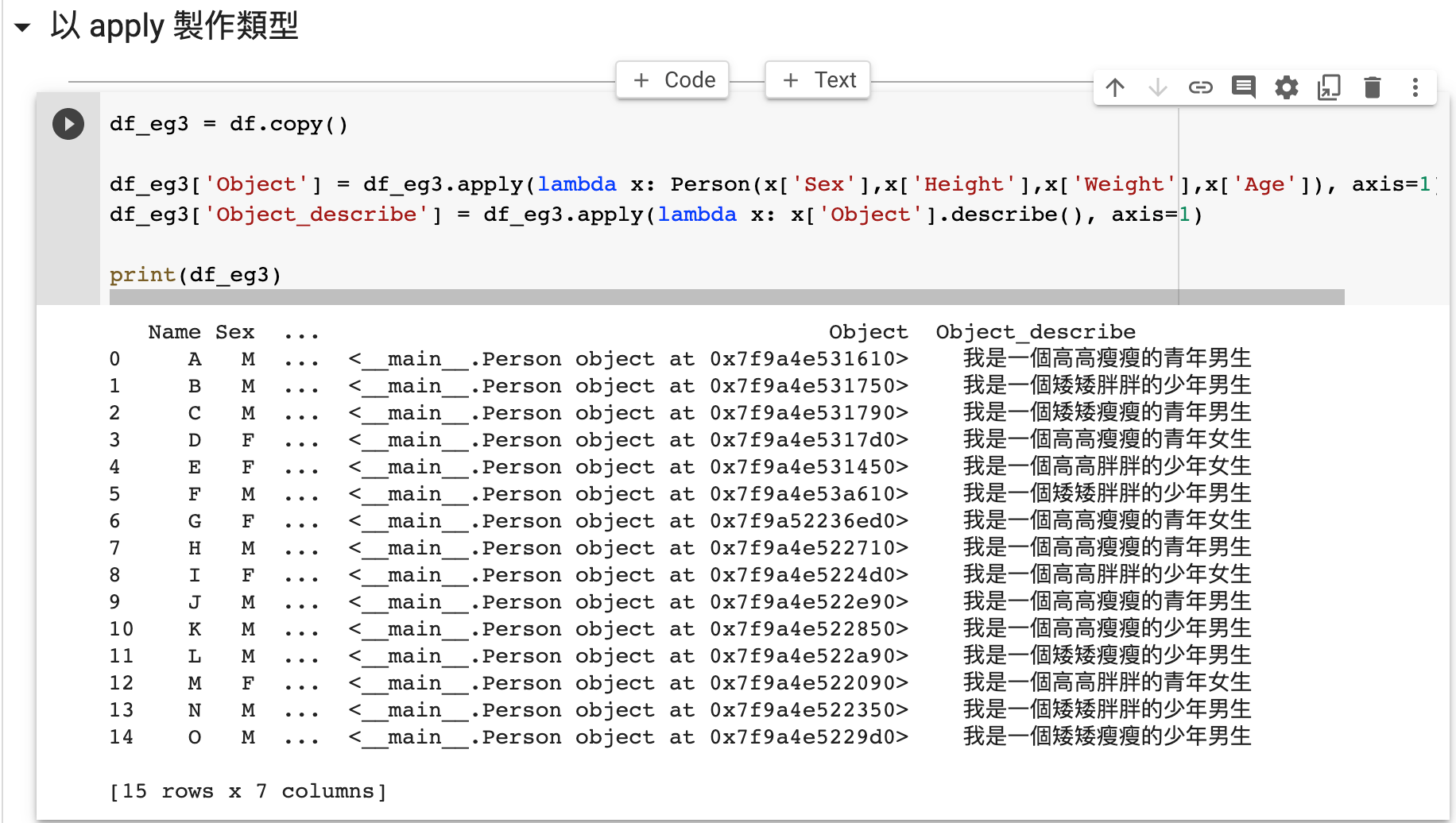
df_eg3 = df.copy() df_eg3['Object'] = df_eg3.apply(lambda x: Person(x['Sex'],x['Height'],x['Weight'],x['Age']), axis=1) df_eg3['Object_describe'] = df_eg3.apply(lambda x: x['Object'].describe(), axis=1) print(df_eg3)
與先前一樣,我們使用 apply lambda ,用每一行(Row)的數據製做一個獨特的 Person。我們把這個數據類型(object)放進原來的 dataframe 的「Object」一列。
我們再以 apply lambda 製做另一個列。這次,我們把每一行 Object 這列裡的 Person 抽出,呼叫這個 Person 的 describe() 功能,並輸出成 Object_describe 一列。
留意在圖裡,我們把完成的 dataframe 列印出來 Object 一列(Column)裡,每一行都是 <__main__.Person object at 0xXXXXXXXX> 的樣式。熟悉編程的同學會發現這個 Object 列儲存的是每一個 Person 的記憶體位置(Pointer)。
編程偽代碼(pseudo-code):
class custom_object:
def __init__(self, arg1, arg2):
self.arg1 = arg1
self.arg2 = arg2
def custom_function(self):
return some_function_of(self.arg1, self.arg2)
df['Custom_Object'] = df.apply(lambda x: custom_object(x['col1'],x['col2'], axis=1)
教學完整代碼
還未使用過 Google Colab Notebook?快來看這篇教學吧:新手 1/3:5 分鐘免安裝學習 Python?Google Colab Notebook 幫緊您!
下一步
我們下一步來看看如何使用 pandas 的 groupby 吧!
其他相關文章:





















