


今天我們來談一下 pandas 其中一個最重要的功能,就是 DataFrame 的 groupby 功能。
顧名思義,groupby 是一個可以把數據組合(group)的功能。這在我們日常生活裡十分常見。比如說,我們求學時,老師會告訴我們全班考試的平均分是什麼。所謂的「平均」就是組合數據的一種方法。
而我們在處理 pandas 數據時,groupby 就是我們把數據(data)轉換成有意思的資訊(information)的途徑。例如透過考試的平均分,我們可以約略知道自己是否跟上了學習進度。
您可能感興趣:
- 如何使用 pandas 的 apply?Dataframe 加入新 Column?Python 數據整合處理!
- pandas map 和 applymap 如何使用?Series 和 DataFrame 各有不同
groupby 的語法
我們學習 groupby 的具體前,我們先來瞭解一下最基本的 groupby 的語法是甚麼:

留意以上我們有 2 個輸入。用例子說明,假如我們想找出男同學與女同學的平均分:
by=[col1, col2]:數據的分組。這裡我們數據的分組便是「性別」{col3: func3, col4: func4}:數據的處理。這裡我們數據的處理便是「平均」(mean)的「分數」
因此,我們想找出男同學與女同學的平均分的話,groupby 的語法便是 df.groupby(by=['性別']).agg({'分數': np.mean})。
groupby 的強大之處,在於它可以處理差不多任何類型的數據。以下會用數個例子說明不同 groupby 的用法。
編程例子
我們會在這篇教學使用免費、免安裝的 Google Colab Notebook。如果您不知道如何使用 Google Colab,可以參考這篇教學:新手 1/3:5 分鐘免安裝學習 Python?Google Colab Notebook 幫緊您!
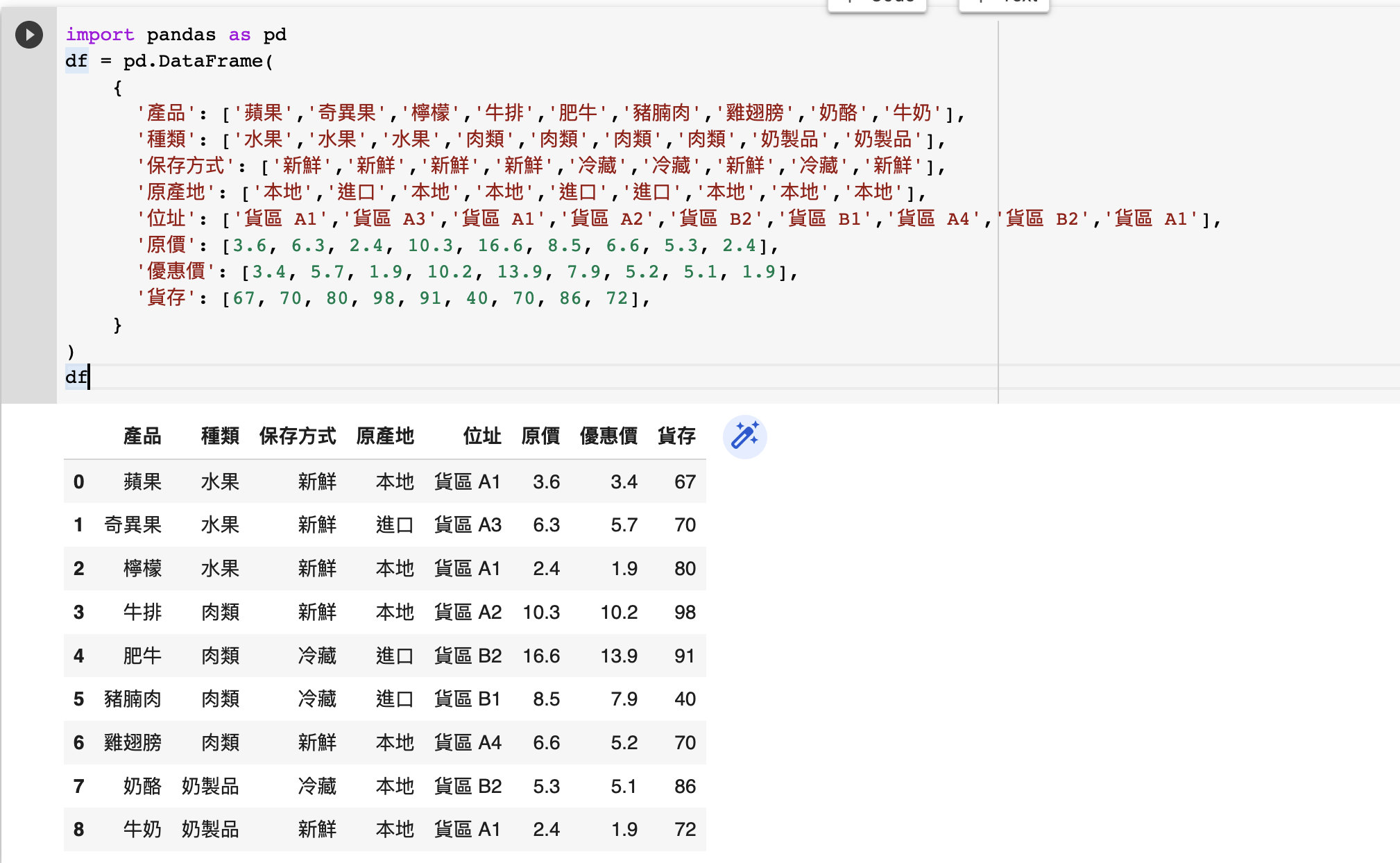
首先我們定義 df 為我們的數據範例:
import pandas as pd
df = pd.DataFrame(
{
'產品': ['蘋果','奇異果','檸檬','牛排','肥牛','豬腩肉','雞翅膀','奶酪','牛奶'],
'種類': ['水果','水果','水果','肉類','肉類','肉類','肉類','奶製品','奶製品'],
'保存方式': ['新鮮','新鮮','新鮮','新鮮','冷藏','冷藏','新鮮','冷藏','新鮮'],
'原產地': ['本地','進口','本地','本地','進口','進口','本地','本地','本地'],
'位址': ['貨區 A1','貨區 A3','貨區 A1','貨區 A2','貨區 B2','貨區 B1','貨區 A4','貨區 B2','貨區 A1'],
'原價': [3.6, 6.3, 2.4, 10.3, 16.6, 8.5, 6.6, 5.3, 2.4],
'優惠價': [3.4, 5.7, 1.9, 10.2, 13.9, 7.9, 5.2, 5.1, 1.9],
'貨存': [67, 70, 80, 98, 91, 40, 70, 86, 72],
}
)
df
註:先按一下綠色按鈕 “Run” 執行代碼,讓您能在 IPython Shell 看到編程結果!
我們的 df 模擬一個超市的數據。每一行(row)的代表一種貨品(例如蘋果、牛排等),而我們每一列(column)有關於這個貨品的資料,例如售價、貨存(stock)等。
實例 1:將文字組合成一行
問題:如何找出每一個種類有甚麼產品?如何找出產品出自甚麼原產地?
| 數據的分組 | 數據的處理 |
|---|---|
['種類'] | {'產品': ', '.join} |
['原產地'] | {'產品': ', '.join} |

import pandas as pd
df = pd.DataFrame(
{
'產品': ['蘋果','奇異果','檸檬','牛排','肥牛','豬腩肉','雞翅膀','奶酪','牛奶'],
'種類': ['水果','水果','水果','肉類','肉類','肉類','肉類','奶製品','奶製品'],
'保存方式': ['新鮮','新鮮','新鮮','新鮮','冷藏','冷藏','新鮮','冷藏','新鮮'],
'原產地': ['本地','進口','本地','本地','進口','進口','本地','本地','本地'],
'位址': ['貨區 A1','貨區 A3','貨區 A1','貨區 A2','貨區 B2','貨區 B1','貨區 A4','貨區 B2','貨區 A1'],
'原價': [3.6, 6.3, 2.4, 10.3, 16.6, 8.5, 6.6, 5.3, 2.4],
'優惠價': [3.4, 5.7, 1.9, 10.2, 13.9, 7.9, 5.2, 5.1, 1.9],
'貨存': [67, 70, 80, 98, 91, 40, 70, 86, 72],
}
)
df.groupby(by=['種類']).agg({'產品': ', '.join})
註:先按一下綠色按鈕 “Run” 執行代碼,讓您能在 IPython Shell 看到編程結果!
import pandas as pd
df = pd.DataFrame(
{
'產品': ['蘋果','奇異果','檸檬','牛排','肥牛','豬腩肉','雞翅膀','奶酪','牛奶'],
'種類': ['水果','水果','水果','肉類','肉類','肉類','肉類','奶製品','奶製品'],
'保存方式': ['新鮮','新鮮','新鮮','新鮮','冷藏','冷藏','新鮮','冷藏','新鮮'],
'原產地': ['本地','進口','本地','本地','進口','進口','本地','本地','本地'],
'位址': ['貨區 A1','貨區 A3','貨區 A1','貨區 A2','貨區 B2','貨區 B1','貨區 A4','貨區 B2','貨區 A1'],
'原價': [3.6, 6.3, 2.4, 10.3, 16.6, 8.5, 6.6, 5.3, 2.4],
'優惠價': [3.4, 5.7, 1.9, 10.2, 13.9, 7.9, 5.2, 5.1, 1.9],
'貨存': [67, 70, 80, 98, 91, 40, 70, 86, 72],
}
)
df.groupby(['原產地']).agg({'產品': ', '.join})
註:先按一下綠色按鈕 “Run” 執行代碼,讓您能在 IPython Shell 看到編程結果!
第一個要介紹的就是如何把同一列的項目組合成一個行。
留意以上的代碼裡,我們在數據的處理裡使用了 {'產品': ', '.join}。如果您熟識列表的合併的話,應該會使用過 join 這一個功能。
如果我們使用 ', '.join([1,2,3,4]) ,輸出便會是一個文字(string) '1, 2, 3, 4' 。同樣道理,我們亦可以把「產品」這一列想像成一個列表,透過 join 可以把它輸出成一個文字,
因此,我們在 .agg({col3: func3}) 的語法裡,func3 就是我們平常會用以處理列表的功能,例如 ', '.join(my_list)。只不過,我們在使用 groupby 時,其實需要把功能作函數(function as an argument),所以便不需要指明 my_list,而需要使用 ', '.join。
很多時,我們需要把數據組合成一個簡單的列表展示出來。這個語法便可以讓我們輕鬆地輸出全部的項目,一覽數據。
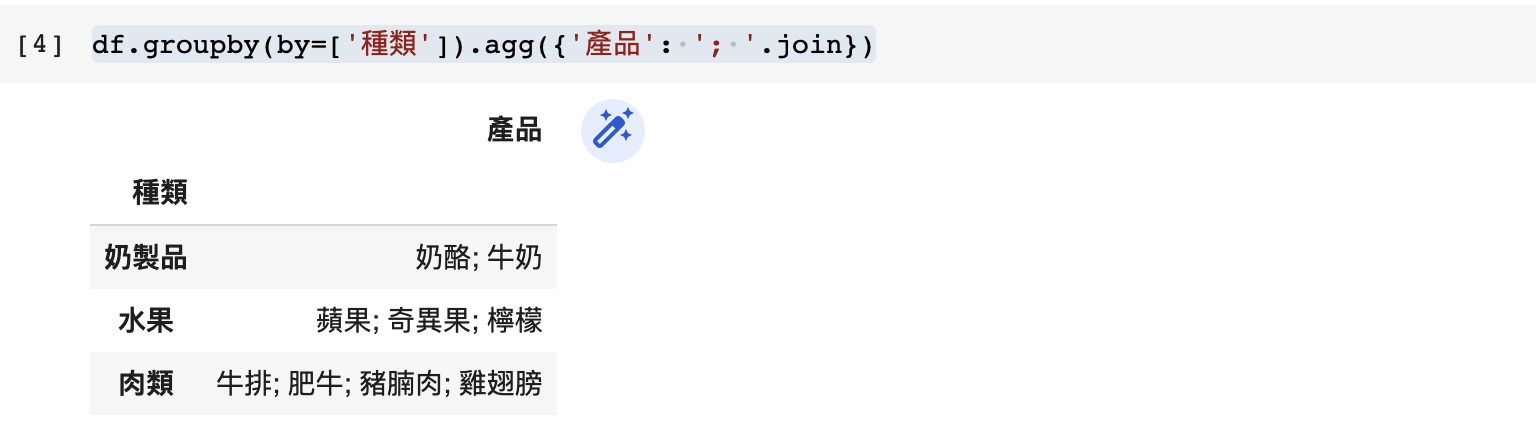
除了使用逗號,我們也可以把語法改成 '; '.join,便會顯示一個以分號相隔的列表。您也可以自訂您需要的分隔,方便在不同地方展示出來:
import pandas as pd
df = pd.DataFrame(
{
'產品': ['蘋果','奇異果','檸檬','牛排','肥牛','豬腩肉','雞翅膀','奶酪','牛奶'],
'種類': ['水果','水果','水果','肉類','肉類','肉類','肉類','奶製品','奶製品'],
'保存方式': ['新鮮','新鮮','新鮮','新鮮','冷藏','冷藏','新鮮','冷藏','新鮮'],
'原產地': ['本地','進口','本地','本地','進口','進口','本地','本地','本地'],
'位址': ['貨區 A1','貨區 A3','貨區 A1','貨區 A2','貨區 B2','貨區 B1','貨區 A4','貨區 B2','貨區 A1'],
'原價': [3.6, 6.3, 2.4, 10.3, 16.6, 8.5, 6.6, 5.3, 2.4],
'優惠價': [3.4, 5.7, 1.9, 10.2, 13.9, 7.9, 5.2, 5.1, 1.9],
'貨存': [67, 70, 80, 98, 91, 40, 70, 86, 72],
}
)
df.groupby(by=['種類']).agg({'產品': '; '.join})
註:先按一下綠色按鈕 “Run” 執行代碼,讓您能在 IPython Shell 看到編程結果!
實例 2:尋找每個組別的數量
問題:如何找出每一個種類有多少產品?如何找出每個原產地有多少產品?
| 數據的分組 | 數據的處理 |
|---|---|
['種類'] | {'產品': len} |
['原產地'] | {'產品': len} |

import pandas as pd
df = pd.DataFrame(
{
'產品': ['蘋果','奇異果','檸檬','牛排','肥牛','豬腩肉','雞翅膀','奶酪','牛奶'],
'種類': ['水果','水果','水果','肉類','肉類','肉類','肉類','奶製品','奶製品'],
'保存方式': ['新鮮','新鮮','新鮮','新鮮','冷藏','冷藏','新鮮','冷藏','新鮮'],
'原產地': ['本地','進口','本地','本地','進口','進口','本地','本地','本地'],
'位址': ['貨區 A1','貨區 A3','貨區 A1','貨區 A2','貨區 B2','貨區 B1','貨區 A4','貨區 B2','貨區 A1'],
'原價': [3.6, 6.3, 2.4, 10.3, 16.6, 8.5, 6.6, 5.3, 2.4],
'優惠價': [3.4, 5.7, 1.9, 10.2, 13.9, 7.9, 5.2, 5.1, 1.9],
'貨存': [67, 70, 80, 98, 91, 40, 70, 86, 72],
}
)
df.groupby(by=['種類']).agg({'產品': len})
註:先按一下綠色按鈕 “Run” 執行代碼,讓您能在 IPython Shell 看到編程結果!
import pandas as pd
df = pd.DataFrame(
{
'產品': ['蘋果','奇異果','檸檬','牛排','肥牛','豬腩肉','雞翅膀','奶酪','牛奶'],
'種類': ['水果','水果','水果','肉類','肉類','肉類','肉類','奶製品','奶製品'],
'保存方式': ['新鮮','新鮮','新鮮','新鮮','冷藏','冷藏','新鮮','冷藏','新鮮'],
'原產地': ['本地','進口','本地','本地','進口','進口','本地','本地','本地'],
'位址': ['貨區 A1','貨區 A3','貨區 A1','貨區 A2','貨區 B2','貨區 B1','貨區 A4','貨區 B2','貨區 A1'],
'原價': [3.6, 6.3, 2.4, 10.3, 16.6, 8.5, 6.6, 5.3, 2.4],
'優惠價': [3.4, 5.7, 1.9, 10.2, 13.9, 7.9, 5.2, 5.1, 1.9],
'貨存': [67, 70, 80, 98, 91, 40, 70, 86, 72],
}
)
df.groupby(['原產地']).agg({'產品': len})
註:先按一下綠色按鈕 “Run” 執行代碼,讓您能在 IPython Shell 看到編程結果!
除了把所有項目展示出來以外,另一個常見的問題時是每一個組別裡有多少項目。
套用了我們 groupby 的框架,我們可以使用 len 這個功能去達成目標。
還記得 len(my_list) 是回傳 my_list 有多少項目的功能嗎?例如 len([1,2,3,4]) 會回傳 4,因為這個列表有 4 個項目。
同樣地,我們在 .agg({col3: func3}) 的語法裡使用 len,便可以找到每一個組別裡有多少項目。
實例 3:將數字加起上來/尋找平均值
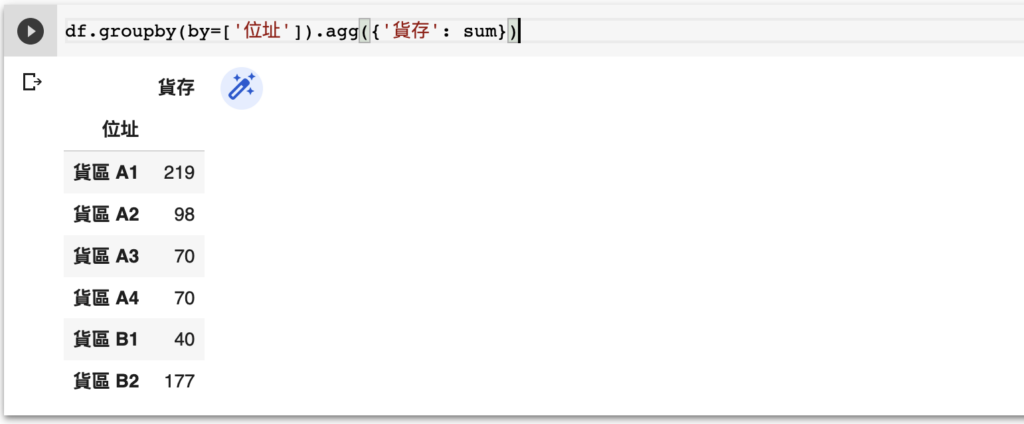
問題:如何找出每個貨區的總貨存是多少?
| 數據的分組 | 數據的處理 |
|---|---|
['位址'] | {'貨存': sum} |
import pandas as pd
df = pd.DataFrame(
{
'產品': ['蘋果','奇異果','檸檬','牛排','肥牛','豬腩肉','雞翅膀','奶酪','牛奶'],
'種類': ['水果','水果','水果','肉類','肉類','肉類','肉類','奶製品','奶製品'],
'保存方式': ['新鮮','新鮮','新鮮','新鮮','冷藏','冷藏','新鮮','冷藏','新鮮'],
'原產地': ['本地','進口','本地','本地','進口','進口','本地','本地','本地'],
'位址': ['貨區 A1','貨區 A3','貨區 A1','貨區 A2','貨區 B2','貨區 B1','貨區 A4','貨區 B2','貨區 A1'],
'原價': [3.6, 6.3, 2.4, 10.3, 16.6, 8.5, 6.6, 5.3, 2.4],
'優惠價': [3.4, 5.7, 1.9, 10.2, 13.9, 7.9, 5.2, 5.1, 1.9],
'貨存': [67, 70, 80, 98, 91, 40, 70, 86, 72],
}
)
df.groupby(by=['位址']).agg({'貨存': sum})
註:先按一下綠色按鈕 “Run” 執行代碼,讓您能在 IPython Shell 看到編程結果!
接下來,我們介紹 Groupby 其中一個最常用的功能,就是把數字整合成有用的資訊。
我們許多時候要按類別加起數字。譬如我們想知道大樓裡每一戶有多少人、證券戶口裡每隻股票的持股有多少等,通通都是按類別加起數字的問題。
就如 sum([1,2,3,4]) 會回傳 10,即列表裡數字的總和一樣,我們也可以在 .agg({col3: func3}) 的語法裡使用 sum,按類把數字疊加。
問題:如何比較不同原產地的產品原價平均,與優惠價平均?
| 數據的分組 | 數據的處理 |
|---|---|
['原產地'] | {'原價': np.mean,'優惠價': np.mean} |

import pandas as pd
import numpy as np
df = pd.DataFrame(
{
'產品': ['蘋果','奇異果','檸檬','牛排','肥牛','豬腩肉','雞翅膀','奶酪','牛奶'],
'種類': ['水果','水果','水果','肉類','肉類','肉類','肉類','奶製品','奶製品'],
'保存方式': ['新鮮','新鮮','新鮮','新鮮','冷藏','冷藏','新鮮','冷藏','新鮮'],
'原產地': ['本地','進口','本地','本地','進口','進口','本地','本地','本地'],
'位址': ['貨區 A1','貨區 A3','貨區 A1','貨區 A2','貨區 B2','貨區 B1','貨區 A4','貨區 B2','貨區 A1'],
'原價': [3.6, 6.3, 2.4, 10.3, 16.6, 8.5, 6.6, 5.3, 2.4],
'優惠價': [3.4, 5.7, 1.9, 10.2, 13.9, 7.9, 5.2, 5.1, 1.9],
'貨存': [67, 70, 80, 98, 91, 40, 70, 86, 72],
}
)
df.groupby(by=['原產地']).agg({'原價': np.mean,'優惠價': np.mean})
註:先按一下綠色按鈕 “Run” 執行代碼,讓您能在 IPython Shell 看到編程結果!
除此之外,我們許多時候亦對數字的平均值感興趣。譬如我們想知道證券戶口裡每隻股票的均價、各國城市的平均人口等,都是一些平均值的問題。
在這裡,我們要解釋一下為何用 numpy。由於 Python 本身沒有一個內置的功能計算一個列表的平均值,我們可以使用 numpy 這個常用的數據處理 library 補充一下這個功能。
除了 np.mean 以外,numpy 還有許多有趣的功能可以讓你計算不同的統計數字(statistics),例如標準差(standard deviation)等。
常見的數字整合功能
以下我們歸納一些常見的數字整合功能。您能找到更多的數字整合功能嗎?
| 數據的處理 | 描述 |
|---|---|
{'原價': sum} | 計算這一列裡,每個分組的總和 |
{'原價': min} | 找出這一列裡,每個分組的最小值 |
{'原價': max} | 找出這一列裡,每個分組的最大值 |
{'原價': np.mean} | 計算這一列裡,每個分組的平均值 |
{'原價': std} | 計算這一列裡,每個分組的標準差 |
{'原價': median} | 找出這一列裡,每個分組的中位數 |
實例 4:多層的分組(multi-level)
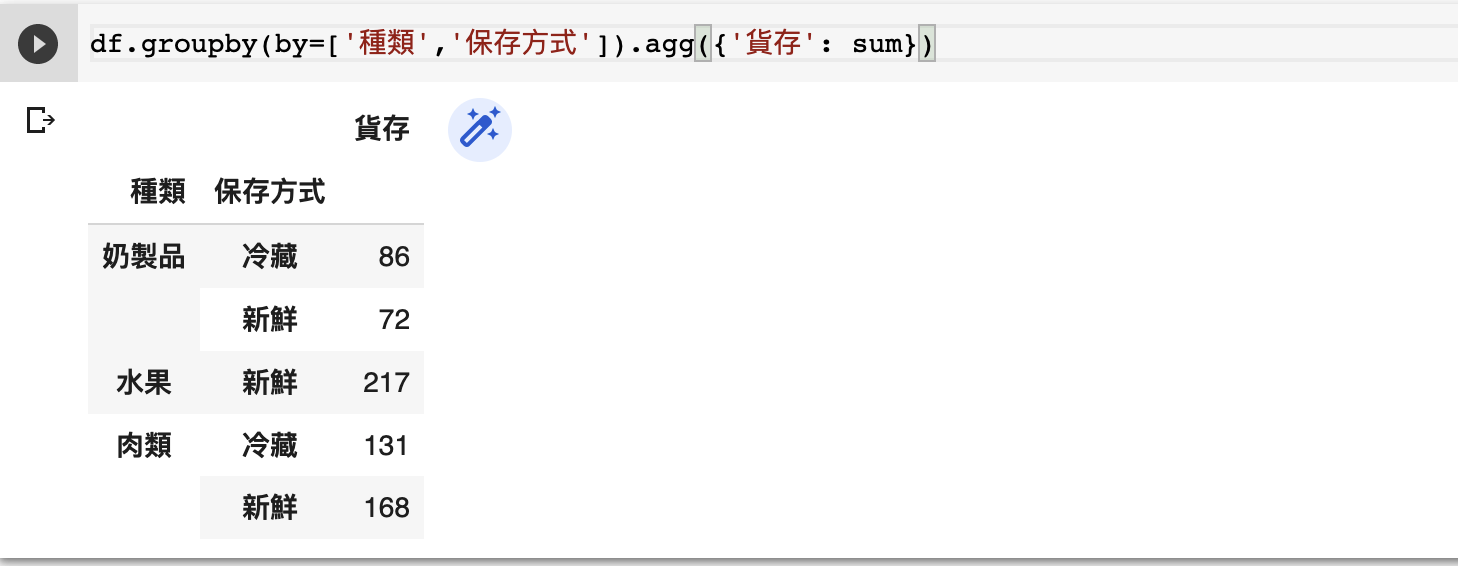
問題:如何找出每種貨品不同保存方式的貨存?
| 數據的分組 | 數據的處理 |
|---|---|
['種類','保存方式'] | {'貨存': sum} |
import pandas as pd
df = pd.DataFrame(
{
'產品': ['蘋果','奇異果','檸檬','牛排','肥牛','豬腩肉','雞翅膀','奶酪','牛奶'],
'種類': ['水果','水果','水果','肉類','肉類','肉類','肉類','奶製品','奶製品'],
'保存方式': ['新鮮','新鮮','新鮮','新鮮','冷藏','冷藏','新鮮','冷藏','新鮮'],
'原產地': ['本地','進口','本地','本地','進口','進口','本地','本地','本地'],
'位址': ['貨區 A1','貨區 A3','貨區 A1','貨區 A2','貨區 B2','貨區 B1','貨區 A4','貨區 B2','貨區 A1'],
'原價': [3.6, 6.3, 2.4, 10.3, 16.6, 8.5, 6.6, 5.3, 2.4],
'優惠價': [3.4, 5.7, 1.9, 10.2, 13.9, 7.9, 5.2, 5.1, 1.9],
'貨存': [67, 70, 80, 98, 91, 40, 70, 86, 72],
}
)
df.groupby(by=['種類','保存方式']).agg({'貨存': sum})
註:先按一下綠色按鈕 “Run” 執行代碼,讓您能在 IPython Shell 看到編程結果!
除了以上 3 個簡單的例子以外,我們有時亦需要多層的數據分組,從而找出有意義的資訊。
舉例說,我們的證券戶口裡有 2 大類股票:成長股(growth stock)與價值股(value stock)。除了這個大分類以外,我們亦希望以持股公司的業務分成幾個行業。所以,我們會有「成長股:食品」、「成長股:科技」、「價值股:食品」、「價值股:工業」等幾個分組。
同樣道理,在以上的例子,我們可能想要知道每類產品不同保存方式的貨存,從而決定如何分配冰櫃。
還記得一開始 groupby 的語法嗎?by=['col1', 'col2'] 就是讓您可以選擇以多於一個的列(column)把數據分組。
當然,如果我們以太多的列作分組,那麼我們輸出的表就跟原來的表沒太大分別了!
實例 5:重複使用同一個列(column)
問題:如何找出每種貨品的平均、最高、最低價格?
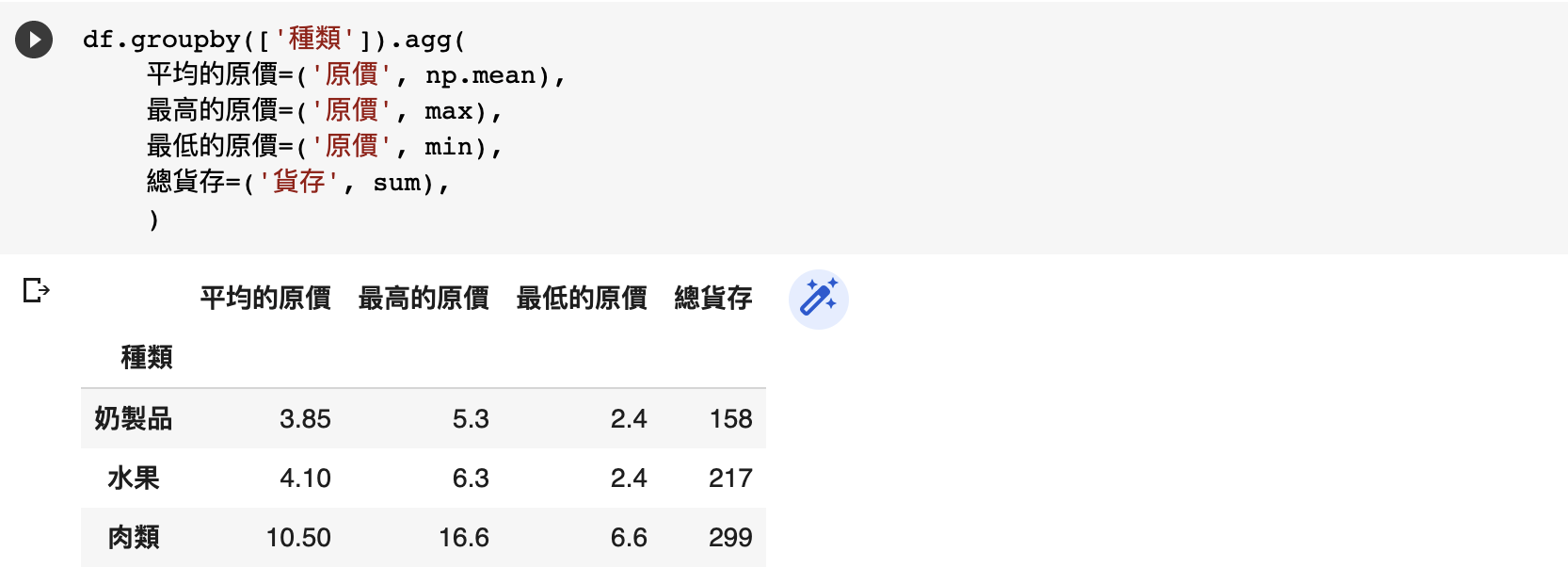
df.groupby(['種類']).agg(
平均的原價=('原價', np.mean),
最高的原價=('原價', max),
最低的原價=('原價', min),
總貨存=('貨存', sum),
)
最後,我們介紹一種特別的 groupby 使用方法。
有時,我們需要同時計算同一個列(column)的不同數據。譬如說,我們想要同時知道每種產品的平均、最高、最低價格,去比較每種產品的定價策略。
這時,我們需要介紹第 2 種 groupby 的語法:

留意現在我們在 agg 的位址裡,除了指明每個列的處理方法以外,我們還可以為輸出的列命名。這讓我們能夠輕鬆重複使用「原價」這個列,但輸出不同的整合(平均、最高、最低)。
對比我們原來的語法:
優點:這個語法能支援重複使用同一個列、和自訂輸出的列名
缺點:如果我們只需要輸出 1 個列,我們便需要重複列名,那就倒不如使用原本的語法
教學完整代碼
最後送給大家這篇教學的 Google Colab 完整代碼。如果您不懂得使用免安裝又好用的 Google Colab Notebook,記得閱讀這篇教學了:新手 1/3:5 分鐘免安裝學習 Python?Google Colab Notebook 幫緊您!
結語
希望您經過這篇教學以後,學會如何使用這個強大的 groupby 功能吧!請繼續留意我們的 pandas 教學系列~





















